Hive安装地址
1 | 1)Hive 官网地址: |
Hive安装部署
Hive安装及配置
1 | (1)把 apache-hive-1.2.1-bin.tar.gz 上传到 linux 的 /software 目录下 |
Hadoop集群配置
1 | (1)必须启动 hdfs 和 yarn |
Hive基本操作
1 | (1)启动 hive |
Hive操作
配置Metastore到MySql
根据官方文档配置参数,拷贝数据到 hive-site.xml 文件中
配置在 /opt/hive/conf 目录下。
1 |
|
上传mysql驱动
上传mysql驱动(mysql-connector-java-5.1.45.jar), 在 /opt/hive/lib 目录下。
启动Hive出现错误
1 | [root@vm1 hive]# bin/hive |
初始化数据库
出现上面的错误,是因为没有初始化数据库。
从Hive 2.1开始,我们需要运行下面的schematool命令作为初始化步骤。例如,这里使用“mysql”作为db类型
1 | [root@vm1 hive]# cd bin |
测试Hive
1 | [root@vm1 hive]# bin/hive |
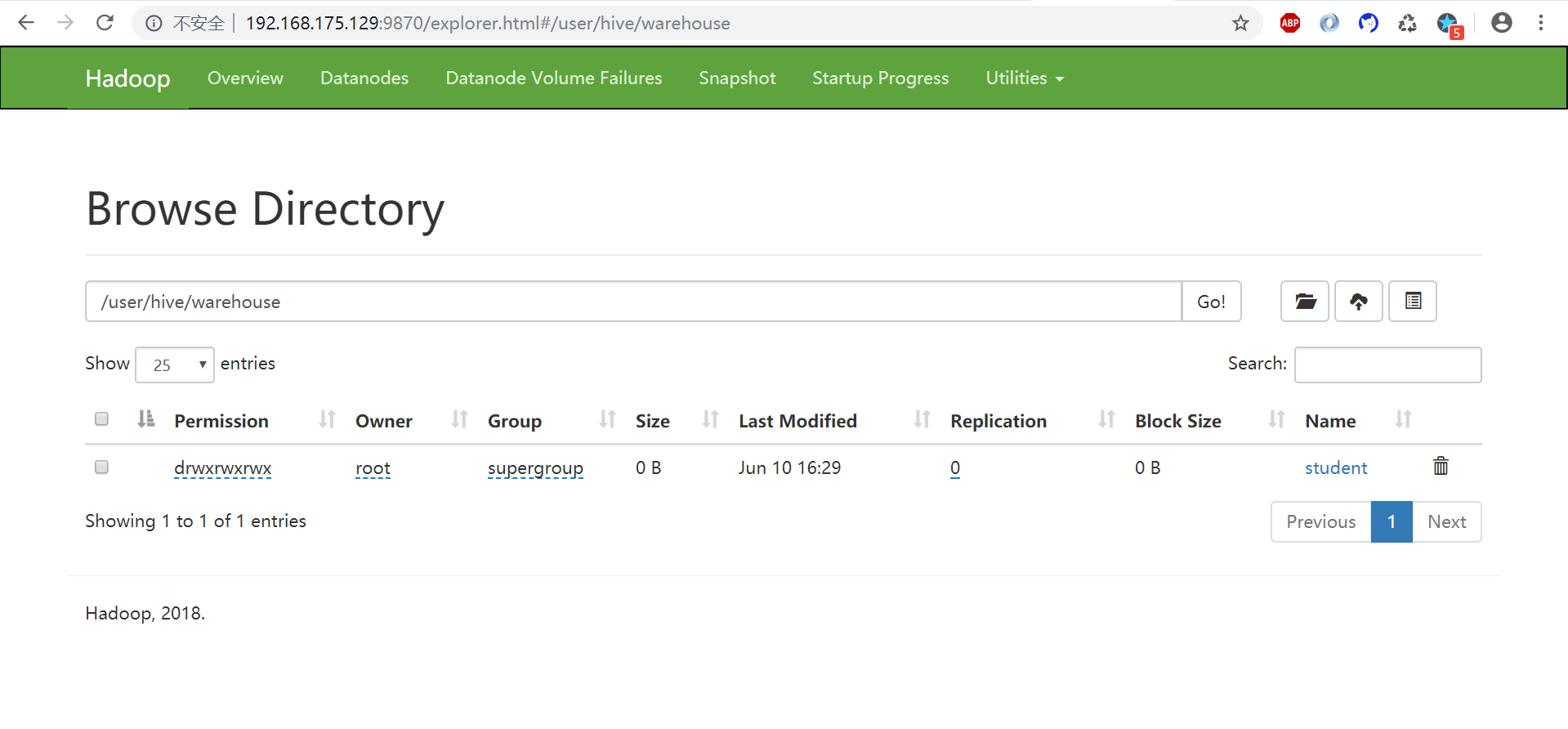
Hive创建表
1 | hive (default)> use default; |
新建表:
Hive中运行任务报错
1 | Ended Job = job_1560152352405_0001 with errors |
失败原因
1 | 经查发现发现/tmp/hadoop/.log提示java.lang.OutOfMemoryError: Java heap space,原因是namenode内存空间不够,jvm不够新job启动导致。 |
解决方法
1 | 将你的hive可以设置成本地模式来执行任务试试: |
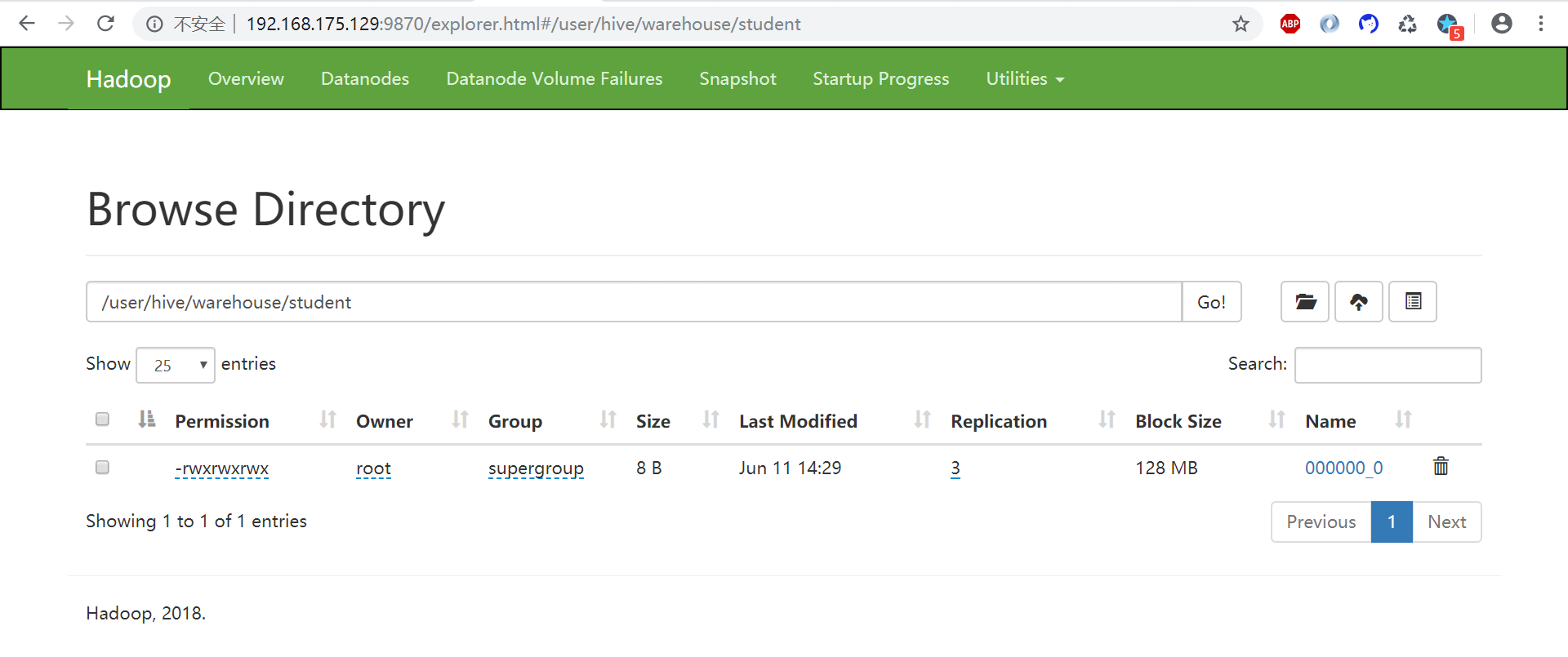
再次插入数据
1 | hive (default)> insert into student values(1000,"ss"); |
在表中插入数据:
将本地文件导入Hive
需求:将本地/opt/datas/student.txt 这个目录下的数据导入到 hive 的 student(id int, name string)表中。
数据准备
在/opt/datas/student.txt 这个目录下准备数据,
[root@vm1 datas]# vim student.txt
1001 zhangshan
1002 lishi
1003 zhaoliu
注意以 tab 键间隔(否则查询出来会出现NULL)
删除已创建的student表,并重新建表
删除已创建的student表
drop table student;
创建student表, 并声明文件分隔符’\t’
create table student(id int, name string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’;
加载/opt/datas/student.txt 文件到 student 数据库表中
load data local inpath ‘/opt/datas/student.txt’ into table student;
1 | hive (default)> drop table student; |

