HDFS产生背景
随着数据量越来越大,在一个操作系统管辖的范围内存不下了,那么就分配到更多的操
作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,
这就是分布式文件管理系统。HDFS 只是分布式文件管理系统中的一种。
HDFS概念
HDFS,它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布
式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
HDFS 的设计适合一次写入,多次读出的场景,且不支持文件的修改。适合用来做数据
分析,并不适合用来做网盘应用。
HDFS优缺点
优点
1 | 1)高容错性 |
缺点
1 | 1)不适合低延时数据访问,比如毫秒级的存储数据,是做不到的。 |
HDFS架构
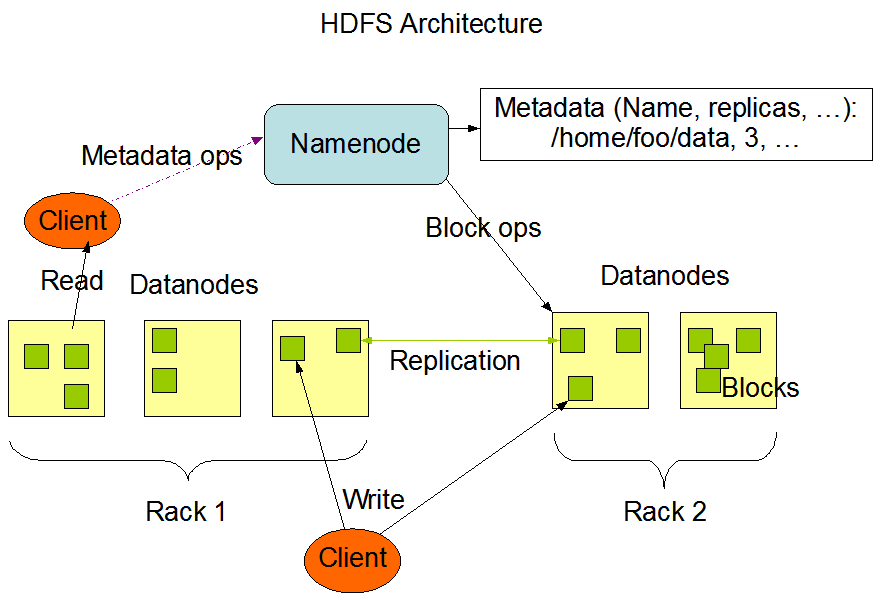
这种架构主要由四个部分组成,分别为 HDFS Client、NameNode、DataNode 和 Secondary
NameNode。下面我们分别介绍这四个组成部分。
1)Client:就是客户端。
(1)文件切分。文件上传 HDFS 的时候,Client 将文件切分成一个一个的 Block,然后进
行存储。
(2)与 NameNode 交互,获取文件的位置信息。
(3)与 DataNode 交互,读取或者写入数据。
(4)Client 提供一些命令来管理 HDFS,比如启动或者关闭 HDFS。
(5)Client 可以通过一些命令来访问 HDFS。
2)NameNode:就是 master,它是一个主管、管理者。
(1)管理 HDFS 的名称空间。
(2)管理数据块(Block)映射信息
(3)配置副本策略
(4)处理客户端读写请求。
3) DataNode:就是 Slave。NameNode 下达命令,DataNode 执行实际的操作。
(1)存储实际的数据块。
(2)执行数据块的读/写操作。
4)Secondary NameNode:并非 NameNode 的热备。当 NameNode 挂掉的时候,它并不能马
上替换 NameNode 并提供服务。
(1)辅助 NameNode,分担其工作量。
(2)定期合并 Fsimage 和 Edits,并推送给 NameNode。
(3)在紧急情况下,可辅助恢复 NameNode。
HDFS 文件块大小
1 | HDFS 中的文件在物理上是分块存储(block),块的大小可以通过配置参数( dfs.blocksize) |
HDFS客户端操作windows环境准备
解压hadoop-3.1.1
本文把hadoop解压在 /d/devlop/hadoop-3.1.1 目录下.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17LEO@LAPTOP-GDA5CI61 MINGW64 /d/devlop/hadoop-3.1.1
$ pwd
/d/devlop/hadoop-3.1.1
LEO@LAPTOP-GDA5CI61 MINGW64 /d/devlop/hadoop-3.1.1
$ ll
total 184
drwxr-xr-x 1 LEO 197121 0 8月 2 2018 bin/
drwxr-xr-x 1 LEO 197121 0 8月 2 2018 etc/
drwxr-xr-x 1 LEO 197121 0 8月 2 2018 include/
drwxr-xr-x 1 LEO 197121 0 8月 2 2018 lib/
drwxr-xr-x 1 LEO 197121 0 8月 2 2018 libexec/
-rw-r--r-- 1 LEO 197121 147144 7月 29 2018 LICENSE.txt
-rw-r--r-- 1 LEO 197121 21867 7月 29 2018 NOTICE.txt
-rw-r--r-- 1 LEO 197121 1366 7月 29 2018 README.txt
drwxr-xr-x 1 LEO 197121 0 8月 2 2018 sbin/
drwxr-xr-x 1 LEO 197121 0 8月 2 2018 share/
添加Hadoop在win上需要的相关库文件,将其添加到hadoop的bin目录中
将windows需要的相关文件,拷贝到 /d/devlop/hadoop-3.1.1/bin 目录下。1
2
3
4
5
6
7
8
9
10
11
12
13
14LEO@LAPTOP-GDA5CI61 MINGW64 /d/workspace-leo/dev/hadoopBin
$ pwd
/d/workspace-leo/dev/hadoopBin
LEO@LAPTOP-GDA5CI61 MINGW64 /d/workspace-leo/dev/hadoopBin
$ ll
total 2872
-rwxr-xr-x 1 LEO 197121 94720 4月 7 2016 hadoop.dll*
-rw-r--r-- 1 LEO 197121 22061 4月 7 2016 hadoop.exp
-rw-r--r-- 1 LEO 197121 36988 4月 7 2016 hadoop.lib
-rw-r--r-- 1 LEO 197121 519168 4月 7 2016 hadoop.pdb
-rw-r--r-- 1 LEO 197121 1246366 4月 7 2016 libwinutils.lib
-rwxr-xr-x 1 LEO 197121 109568 4月 7 2016 winutils.exe*
-rw-r--r-- 1 LEO 197121 896000 4月 7 2016 winutils.pdb
配置hadoop的环境变量
1 |
|
配置pom文件
1 | <properties> |

